Projet thèses
L'objectif de ce projet, réalisé sur deux semestres, est de créer un site en PHP repertoriant toutes les thèses soutenues en France depuis 1985. Pour cela, on s'appuie sur un jeu de données publique disponible sur datagouv.
Le premier objectif du projet consiste à transferer les données dans une base de données SQL pour les exploiter ensuite sur le site. Le tout est réalisé à l'aide d'un script d'importation codé en PHP, qui permet d'importer ligne par ligne les thèses contenues dans le fichier JSON de 2 Go.
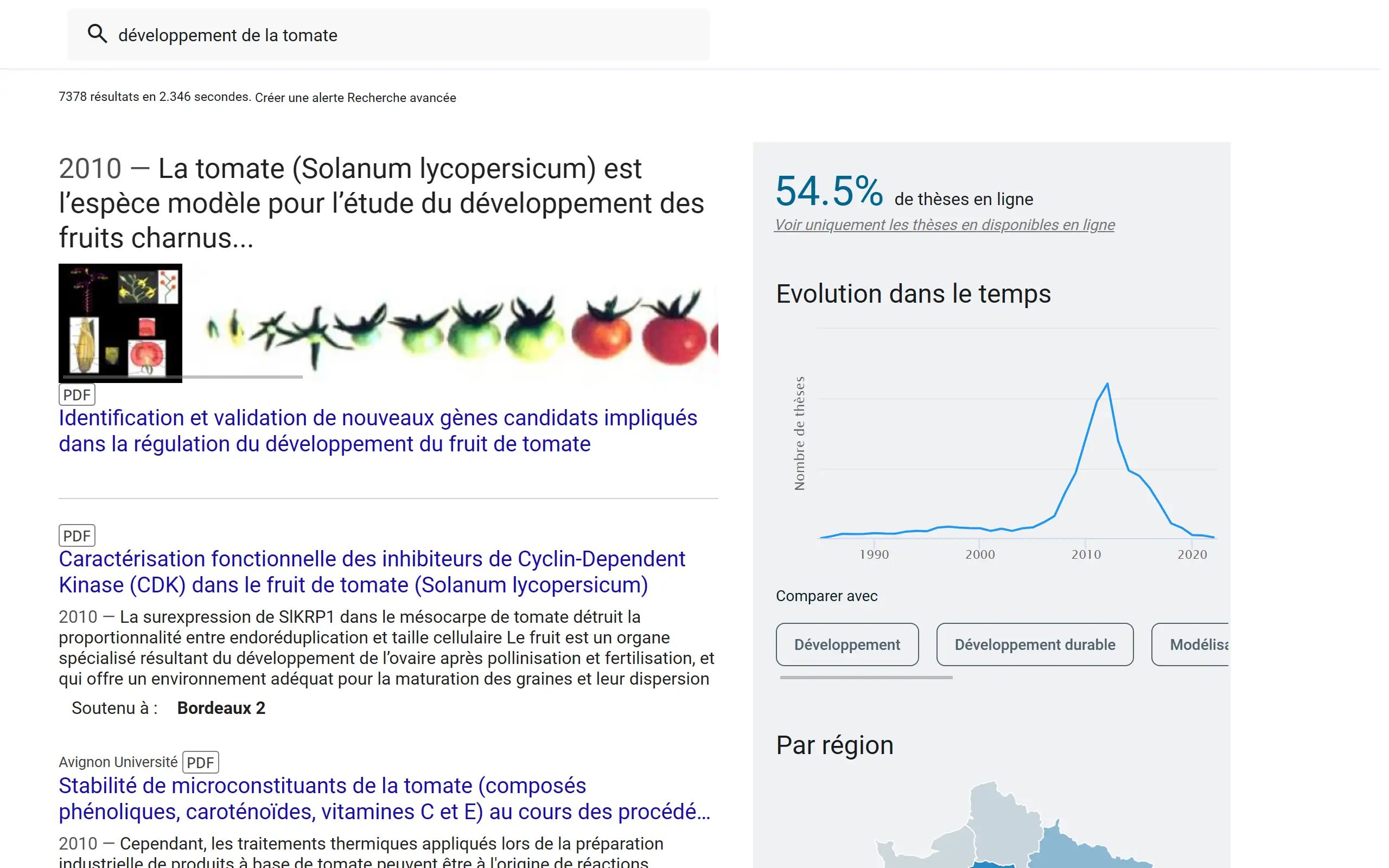
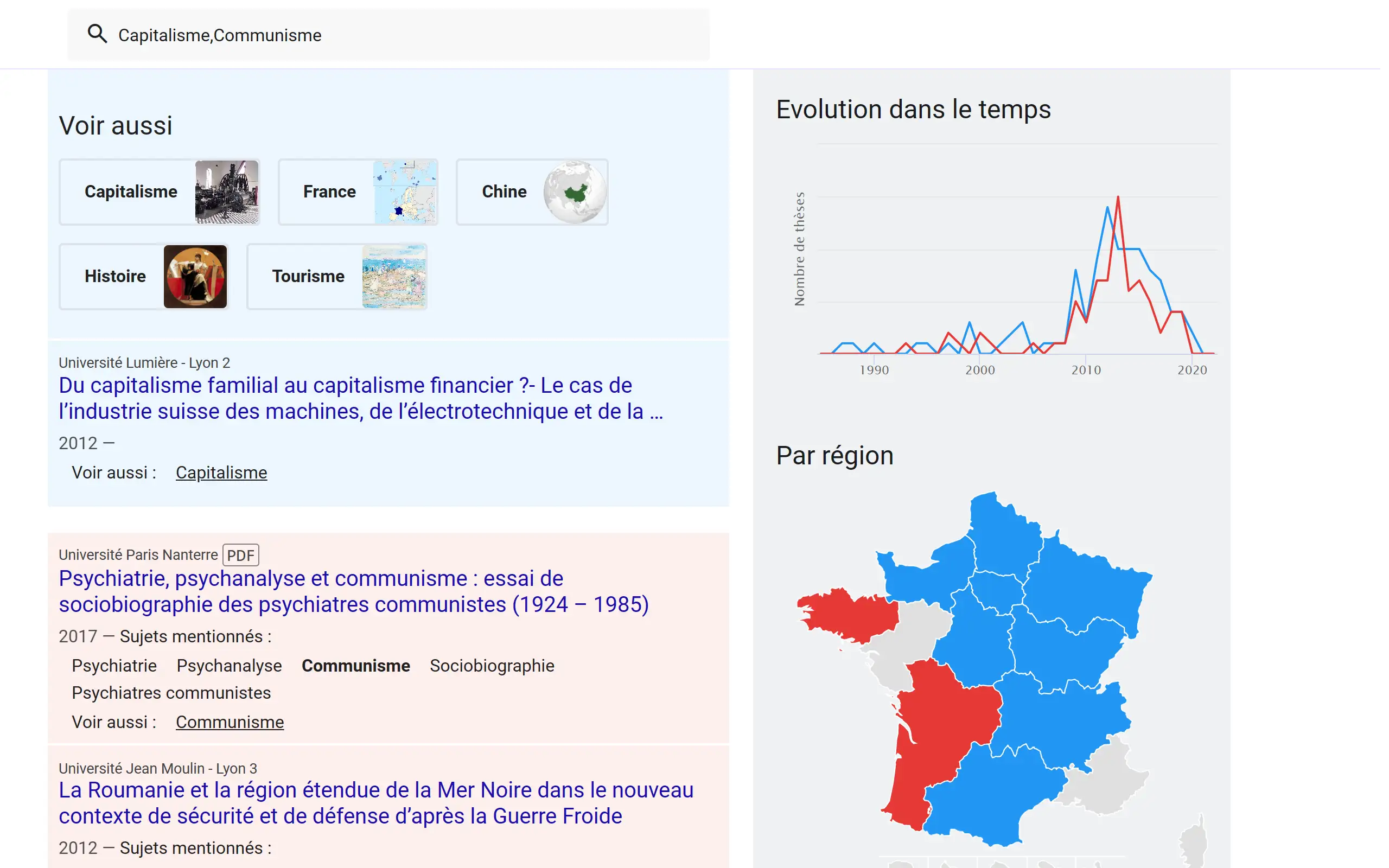
A l'aide de ces données, on affiche quelques graphiques et informations sur le total des thèses contenues dans la base de données. On peut aussi afficher des graphiques et des résultats en fonction d'une recherche, plus ou moins précise.
fonctionnalités principales
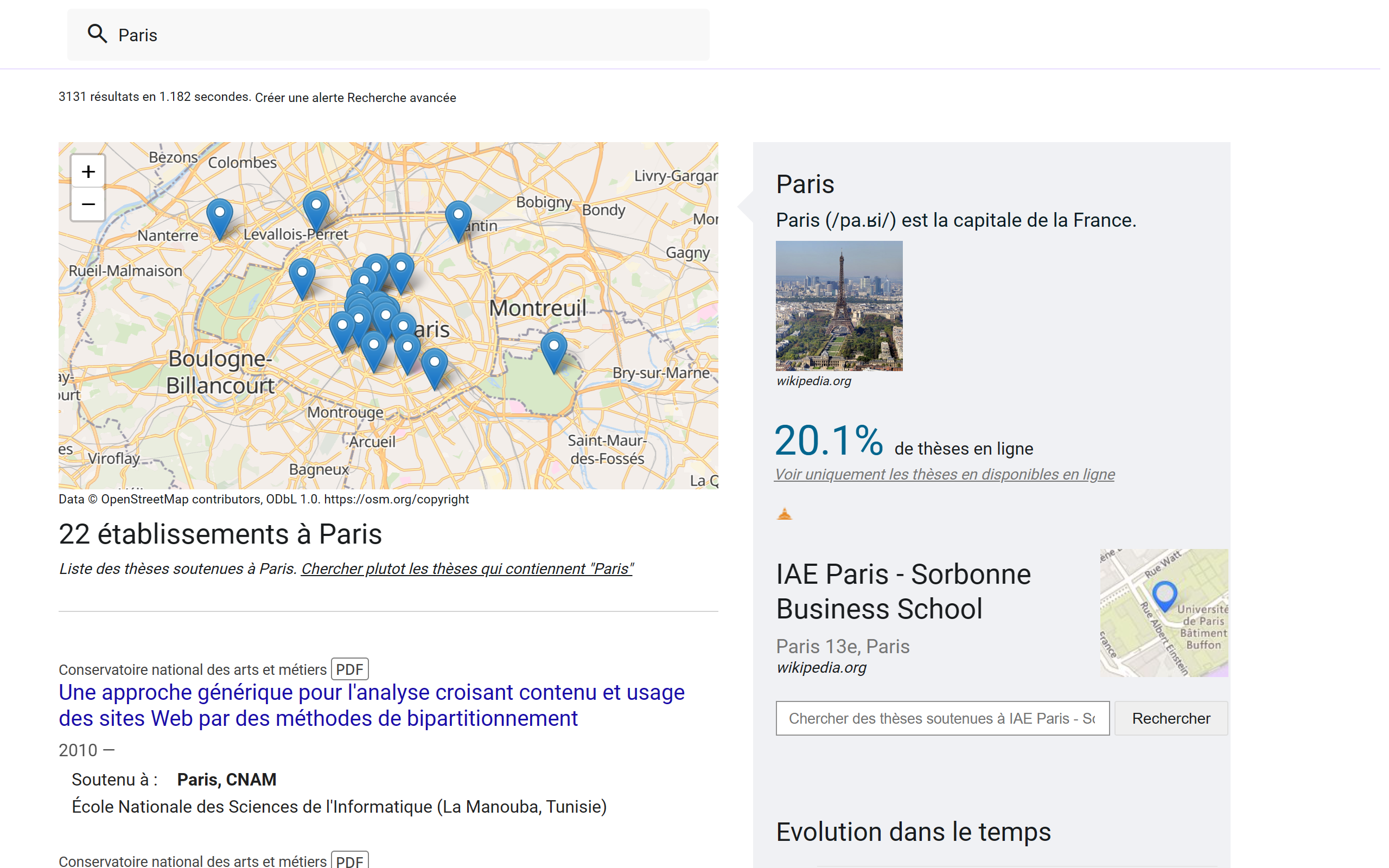
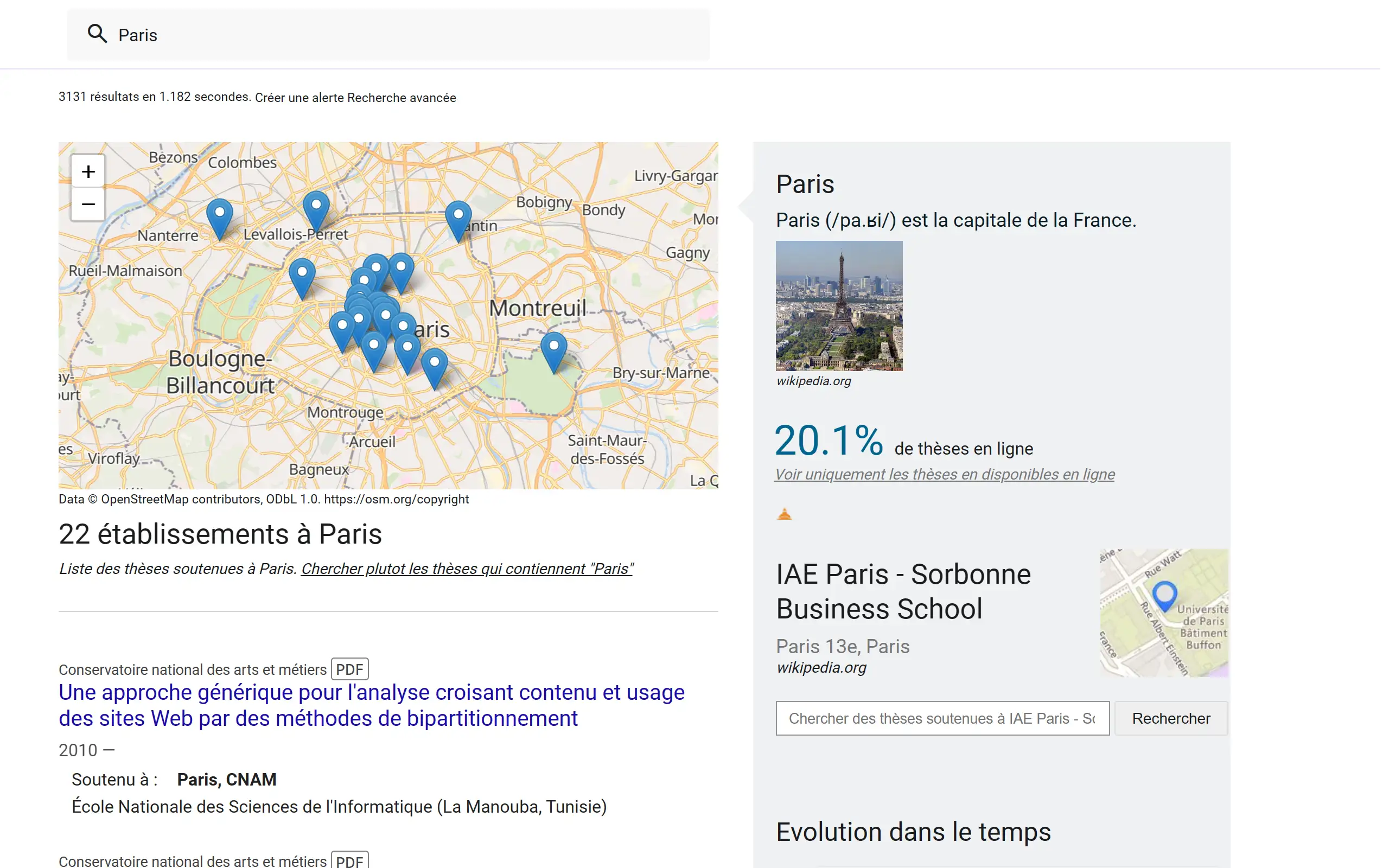
Localised search
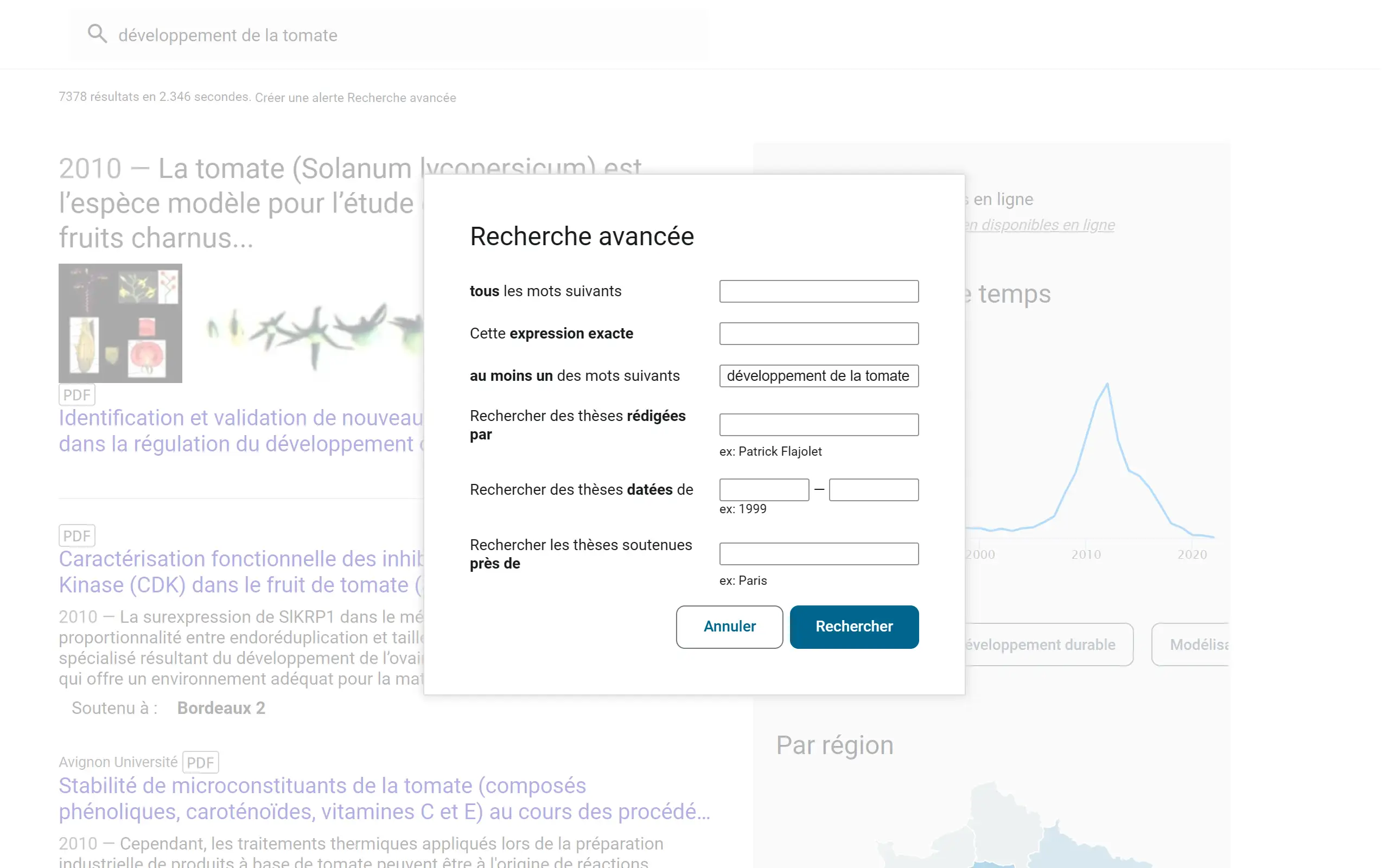
En entrant un nom de ville, vous accédez aux thèses soutenues dans cette ville. Il est possible de localiser une recherche en passant par la recherche avancée.
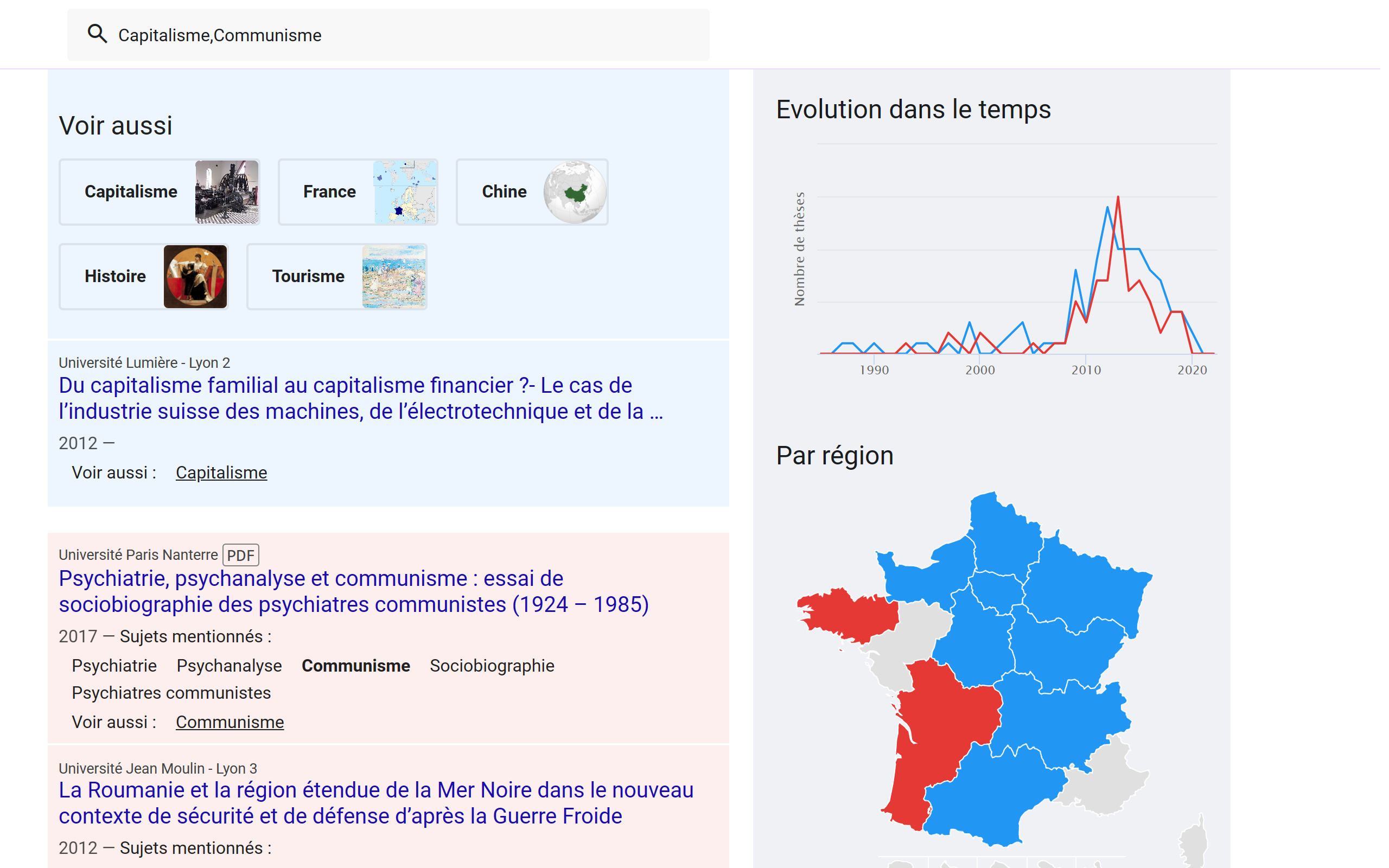
Compare searches
Comparez les statistiques globales de plusieurs recherches à la fois, jusqu'à 4 comparaisons.
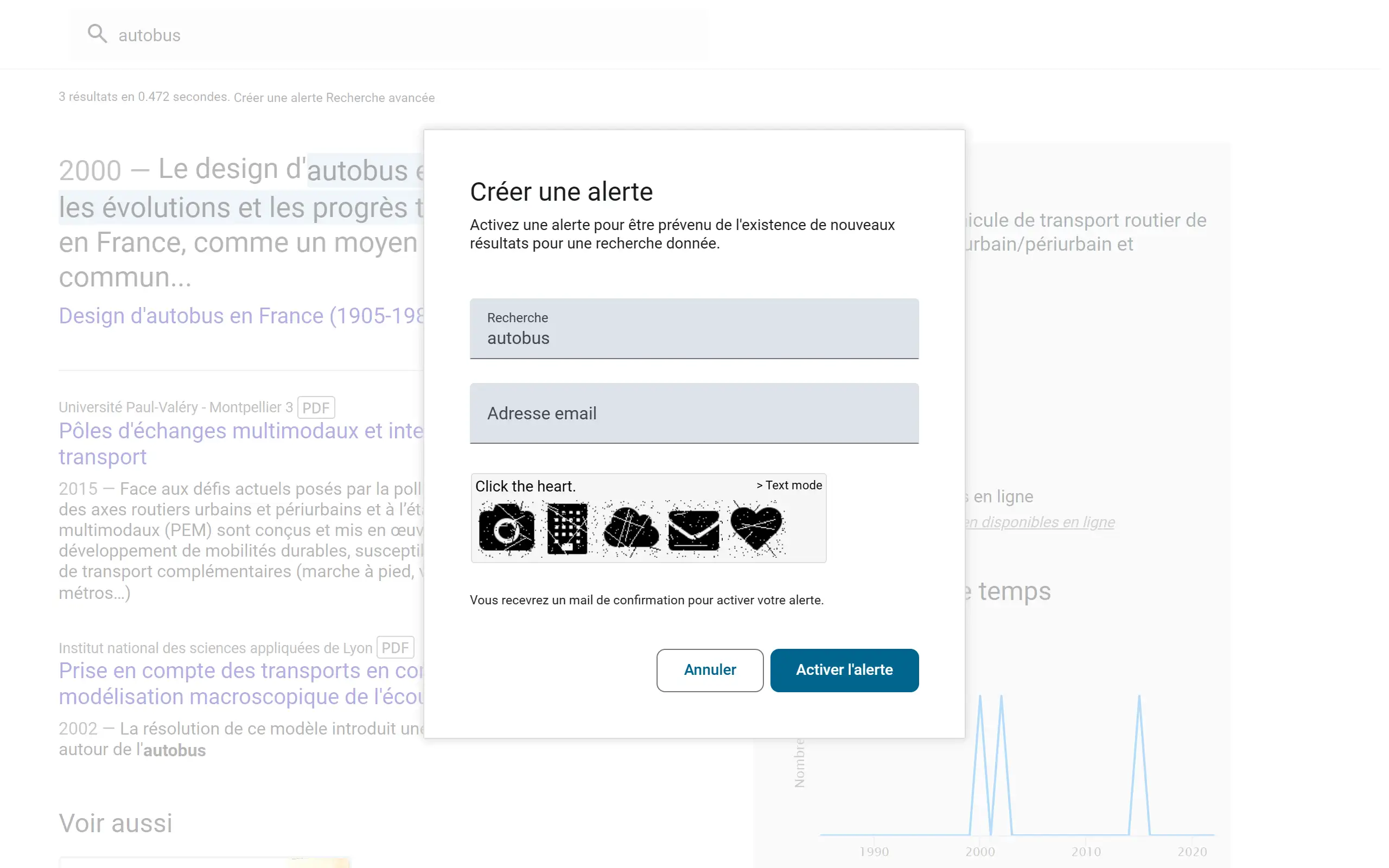
Create alerts
Entrez votre adresse email sur une recherche pour recevoir un mail lorsque de nouvelles thèses seront publiées sur ce domaine.
Résultats de recherche
Le gros travail sur le site a été l'affichage des résultats de recherche. J'ai voulu, pour rendre les informations claires, reproduire une interface style moteur de recherche, et axer tout mon site sur la recherche.
Chaque résultat peut être affiché differemment en fonction du contexte. Par exemple, lorsque la description contient les mots de la recherche, ils sont surlignés dans le texte. Quand il s'agit des sujets, une liste de tous les sujets est affichée. Les sommaires contenus dans le resumé de chaque thèses est aussi automatiquement detecté pour fourni un affichage par puces numérotées.
Images
Certains résultats inclus des images. Cela peut paraitre simple, mais il était compliqué de récuperer des images pour un thèse donnée. En effet, il n'existe aucune image dans le jeu de données, elles proviennent en fait du PDF, qui est scrappé par le site, dans le cas des thèses qui sont disponibles sur internet.
Le processus de scrapping etant très lourd, une mise en cache a été necessaire. Au dela de ca, le processus était tellement long qu'il a aussi fallu l'appeler après le chargement des résultats de recherche. Les images chargent donc indépendamment du reste.
Par auteur
En tapant le nom d'un auteur, on retrouve toutes les thèses qu'il a soutenues. De plus, on peut filtrer chaque recherche en fonction d'un auteur à l'aide de la recherche avancée.